
How to implement text to speech with OpenAI API and Node.js?
How to implement text to speech with OpenAI API and Node.js?

.webp?width=440&height=256&name=frame_136%20(1).webp)


The SpeechSynthesis API
But that changed when the SpeechSynthesis API came out. Built into any modern web browser.
This is a dead simple piece of code that your can launch in your browser console.

Yes, it still sounds like a tin can robot, but there is quite a large list of additional voices you can choose from. Furthermore, you can tweak the speed and pitch of the voice to your liking. All it does is read the text you give it.
Great as an addition to a blog, video or as an aid for the visually impaired. I love the fact that you don't really need any additional prerequisites to use this. SpeechSynthesis API is plug-and-play in any browser (well the good ones).
But you can make text-to-speech even better, more human!
How to use OpenAI API to generate speech
This method will create an mp3 audio file, that you will need to save, later host and embed on a website. To begin, you'll need an OpenAI account, some credits and a python or node environment ready to go.
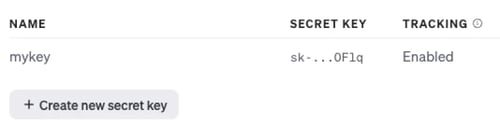
1: Get an OpenAI account and create a secret key
It’s really simple to create an account and generate a key. https://platform.openai.com/api-keys
NOTE: Copy the secret key to a safe space, after you close the modal window you’ll never see the key again and you’ll have to generate another one.
1a: Make sure you have some credits to generate
Learned this the hard way, trying to debug my code, when all the API needed was some of my money to run.
I charged my account with $10 and was ready to go.
OpenAI API works on tokens. A token is about 4 characters (or an english word).
In any case a one thousand character long fragment of text pushed through the TTS (text-to-speech) API will cost $0.030. Which isn’t actually that bad. I converted a couple of my blog posts to audio and paid $0.23.
2: Create a Node.js script that will access the API
I set up some basics like `fs` and `path` to be able to manage the file and imported the OpenAI package.
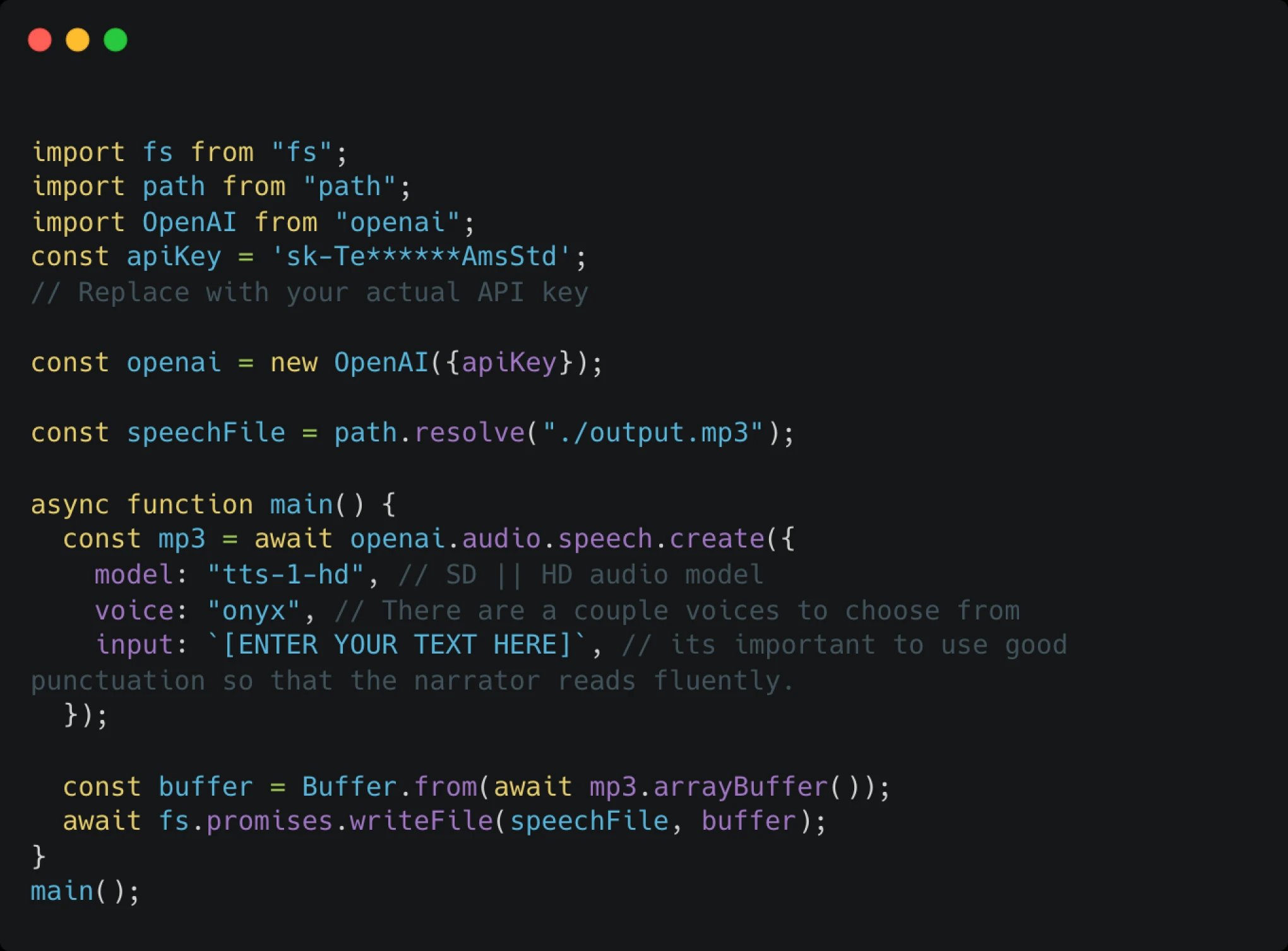
Create a new instance of the OpenAI API, pass your API secret key and you’ll be ready to generate audio files. Check the full documentation for more params that you can pass into the script.
You access the TTS with the openai.audio.speech method.
To use the method you need to pass 3 things:
- - An input (which is just your text)
- - Select a Voice
- - Choose the quality model
There is a SD model that uses less tokens, and a HD that uses more. I’m no audiofile, but I can’t really tell the difference between a SD and HD file.
Pick a voice for your AI bot to talk in. When writing this article there were 6 to choose from. Some sounded normal, others very American, and also about 2 female voices. Onyx is my favorite, super manly :P But also calm and e-booky voice that is very pleasant to listen to.

Finally add your input. The text you want to have spoken by AI.
Top tip, use the backticks ` ` and format your text. Include good punctuation and break up your text into paragraphs. The AI sounds a lot better then.
It will make reading a lot smoother as the AI actually does pitch variations in audio to further make it sound like a human audiobook narrator.
Top tip number 2: Sometimes you might need to write words down phonetically. Most of the time the AI does abbreviations well but sometimes it’s better to help it. For example lists: it’s far better to type out “step number 1” instead of just “1”.
3: Run the script & save your file
OpenAI Whisper, that's how the text to speech model is called, will generate an .mp3 file.
Use Node’s file saving system to write the file to a catalogue.
And that’s it!
You’ll have a audio file read by a wonderful AI voice.
Be aware that this process can take a while to generate. So if you are planning to narrate an entire book, it would be best to break the input into chunks.

